Data Transformation using .NET and XSLT based Gateway component.
In this post we will explore how we can leverage XSLT transformation to build an transformation pipeline in .NET. It will showcase a extract, transform and load scenario for a custom datasource.
The Importance of Data Transformation
In modern enterprise applications, data transformation is a critical process that enables systems to communicate, integrate, and operate cohesively. As organizations increasingly rely on diverse systems—ERP, CRM, databases, APIs, and third-party services—data often arrives in inconsistent formats. In large enterprises, it is critical that the data is accessible in a common format at one place. To make this data usable, it must be transformed into a standardized, canonical format.
This is especially vital when building a gateway or middleware layer that aggregates data from multiple sources. Without transformation:
- Data inconsistencies can lead to processing errors.
- Downstream systems may reject or misinterpret data.
- Business logic becomes tightly coupled to source-specific formats.
- The downstream system needs to consider data formats of all upstream applications.
This makes the client system unncessarily complex and often goes through frequent changes.
By implementing a canonical data model, enterprises can:
- Decouple internal systems from external data formats.
- Simplify integration logic.
- Improve maintainability and scalability.
- Provides a unified API model to access all data in a consistent way.
- Development of critical components like monitoring, logging and analysis becomes easy as these components only need to deal with one format.
There are multiple products in market that help achieve this functionality. However our focus here is to design & develop a custom enterprise component that will key features. This let organization manage cost effectively. This approach is mostly used by product based firms which needs full control on feature without giving up on IP rights.
Below is the picture to demonstrate the problem
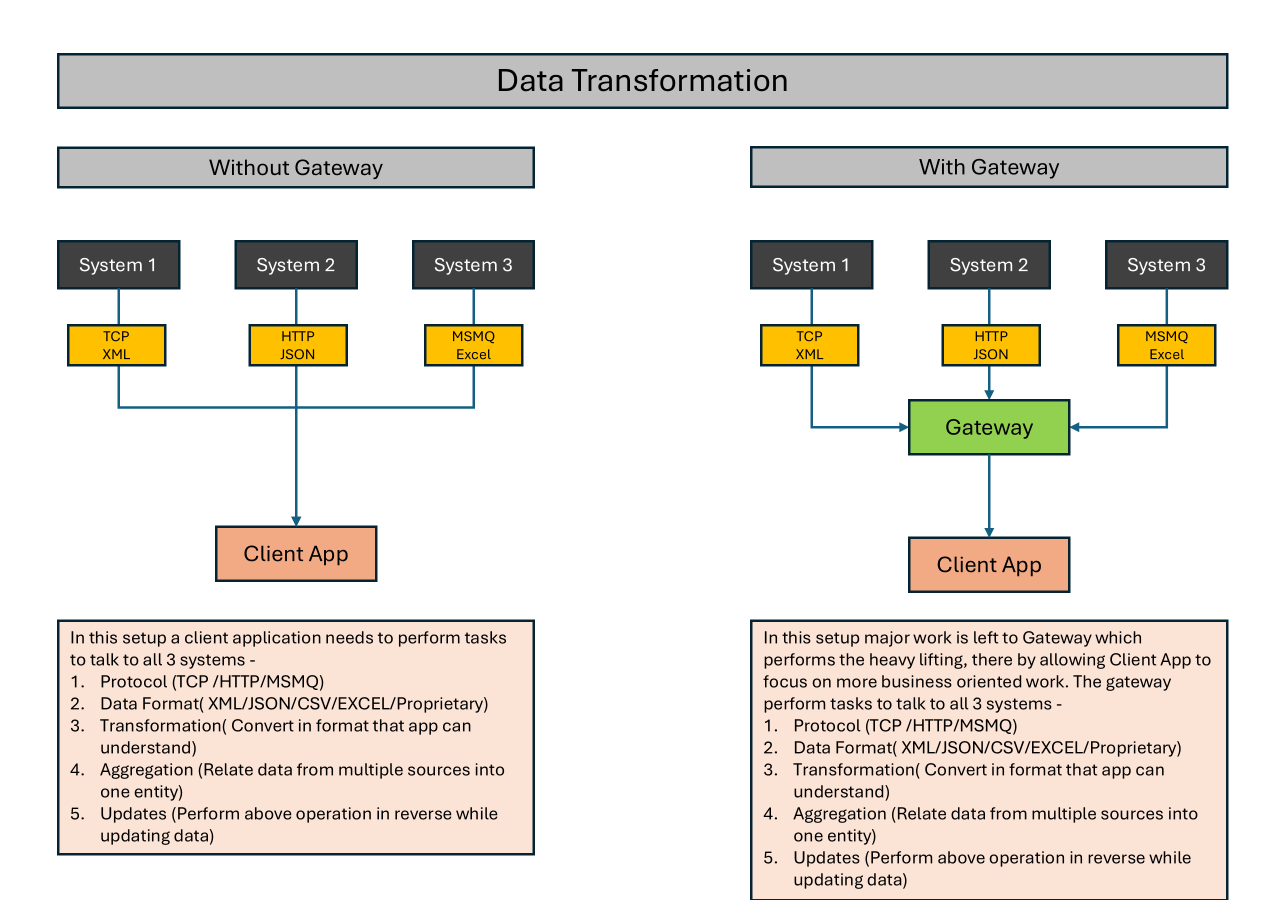
Why XML and XSLT?
XML (eXtensible Markup Language) is a widely adopted standard for structured data representation. It is:
- Self-descriptive and human-readable.
- Schema-driven, allowing validation.
- Platform-independent, making it ideal for cross-system communication.
XSLT (eXtensible Stylesheet Language Transformations) is a declarative language designed specifically for transforming XML documents. It excels in:
- Mapping one XML structure to another.
- Filtering, sorting, and restructuring data.
- Generating different output formats (XML, HTML, plain text).
Combining XSLT + .NET for a middlwware developmemt
.NET provides native support for XML and XSLT manipulations through namespaces like System.Xml, System.Xml.XPath, and System.Xml.Xsl. It has rich support for reading, wirting, transforming and searching XML based documents. This enables:
- Efficient transformation using
XslCompiledTransform, which compiles XSLT for performance. - XPath queries for precise data extraction and manipulation.
- Streaming support for processing large XML files without loading them entirely into memory.
This makes the combination of XML, XSLT, and C# ideal for building high-volume, high-performance transformation pipelines.
2. Understanding the Core Technologies
I am assuming a prior knowledge of XML, XSLT and .NET ecosystem. For a quick reference on these technologies, please refer the below -
XML Basics : A Quick Summary
What is XML?
For starters, XML (eXtensible Markup Language) is a markup language designed to store and transport data. It is both human-readable and machine-readable, making it ideal for data exchange between systems.
Key Features
- Self-descriptive: Data is wrapped in tags that describe its meaning.
- Platform-independent: Works across different systems and technologies.
- Hierarchical structure: Data is organized in a tree-like format.
- Extensible: You can define your own tags and structure.
Basic Syntax
1
2
3
4
5
<person>
<name>John Doe</name>
<age>30</age>
<email>john@example.com</email>
</person>
XSLT Basics: A Quick Summary
What is XSLT?
XSLT is a declarative language used to transform XML documents into other formats such as:
- Another XML structure
- HTML for web display
- Plain text or CSV
- JSON (with some effort)
It is part of the XSL (Extensible Stylesheet Language) family and works by applying transformation rules defined in an XSLT stylesheet.
How XSLT Works
- XSLT uses templates to match elements in the source XML.
- It applies XPath expressions to navigate and select nodes.
- The transformation engine processes the XML and outputs a new document based on the rules.
Basic Syntax Example
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
<!-- Source XML -->
<person>
<name>John</name>
</person>
<!-- XSLT Stylesheet -->
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/person">
<html>
<body>
<h1><xsl:value-of select="name"/></h1>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
Output file after transformation
1
2
3
4
5
<html>
<body>
<h1>John<h1>
</body>
</html>
C# Support for XML and XSLT: A Practical Summary
Overview
C# and the .NET Framework provide robust, high-performance support for working with XML and XSLT. These capabilities are essential for building transformation pipelines, especially in enterprise applications.
Key Namespaces and Classes
| Namespace | Purpose |
|---|---|
System.Xml | Core XML support (DOM, readers, writers) |
System.Xml.XPath | XPath querying support |
System.Xml.Xsl | XSLT transformation engine |
System.Xml.Schema | XML Schema validation |
Optimized Classes for Performance
XmlReader/XmlWriter: Forward-only, streaming access to XML. Ideal for large files.XslCompiledTransform: Compiles XSLT stylesheets for fast, reusable transformations.XPathNavigator: Efficient, read-only cursor for XPath queries.
Sample: Transform XML Using XSLT with XPath
Sample XML (input.xml)
1
2
3
4
5
6
7
<employees>
<employee>
<id>101</id>
<name>Jane Doe</name>
<department>Engineering</department>
</employee>
</employees>
Sample XSLT (‘transform.xslt’)
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/employees">
<html>
<body>
<h2>Employee List</h2>
<ul>
<xsl:for-each select="employee">
<li>
<xsl:value-of select="name"/> -
<xsl:value-of select="department"/>
</li>
</xsl:for-each>
</ul>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
C# Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
using System;
using System.Xml;
using System.Xml.Xsl;
using System.Xml.XPath;
class Program
{
static void Main()
{
// Load XML using XmlReader for performance
using XmlReader xmlReader = XmlReader.Create("input.xml");
// Load and compile the XSLT
XslCompiledTransform xslt = new XslCompiledTransform();
xslt.Load("transform.xslt");
// Create output writer
using XmlWriter writer = XmlWriter.Create("output.html");
// Apply transformation
xslt.Transform(xmlReader, writer);
Console.WriteLine("Transformation complete. Output saved to output.html");
}
}
Output of the XSLT Transformation
The transformation will generate an HTML file (output.html) with the following content:
1
2
3
4
5
6
7
8
<html>
<body>
<h2>Employee List</h2>
<ul>
<li>Jane Doe - Engineering</li>
</ul>
</body>
</html>
Designing the Architecture for Transformation Engine
I am going to describe about a potential architecture that can implemented for a transformation engine. In my future post, I will also show an implementation of this architecture. Lets get in !!!
Designing a robust and scalable data transformation engine requires careful planning of its components, data flow, and operational concerns. In this section I will outline the key architectural elements and considerations when building such a pipeline based transformation architecture.
Core Components of the Transformation Engine
A typical transformation pipeline consists of the following components:
1. Input Handler
Purpose: Ingests raw data from various sources and prepares it for transformation.
Responsibilities:
- Accept data from connectors (e.g., APIs, files, queues).
- Normalize input into a consistent XML format.
- Perform initial validations (e.g., well-formed XML).
2. Schema Validator
Purpose: Ensures that incoming XML adheres to predefined schemas (XSD).
Responsibilities:
- Validate structure and data types.
- Reject or quarantine invalid documents.
- Log validation errors for diagnostics.
3. XSLT Processor
Purpose: Applies transformation logic using XSLT stylesheets.
Responsibilities:
- Load and compile XSLT files.
- Apply transformations to input XML.
- Support parameterized transformations.
- Handle conditional logic, loops, and formatting.
4. XPath Engine
Purpose: Enables querying and navigating XML documents.
Responsibilities:
- Extract specific nodes or values.
- Support dynamic rule-based transformations.
- Enable filtering and conditional processing.
5. Canonical Model Mapper
Purpose: Maps source data to a canonical data model.
Responsibilities:
- Apply business rules and mappings.
- Ensure consistency across different source formats.
- Output standardized XML for downstream systems.
6. Error Handler
Purpose: Captures and manages transformation errors.
Responsibilities:
- Catch runtime exceptions during transformation.
- Log detailed error messages and stack traces.
- Route failed messages to error queues or retry mechanisms.
7. Output Dispatcher
Purpose: Sends transformed data to target systems.
Responsibilities:
- Deliver data via APIs, message queues, or file systems.
- Support multiple output formats (XML, JSON, flat files).
- Ensure delivery guarantees (e.g., at-least-once, exactly-once).
8. Monitoring & Logging Module
Purpose: Provides observability into the transformation process.
Responsibilities:
- Track processing time, throughput, and error rates.
- Generate logs for auditing and debugging.
- Integrate with monitoring tools (e.g., Prometheus, ELK, Azure Monitor).
9. Configuration Manager
Purpose: Manages dynamic configuration of the engine.
Responsibilities:
- Load transformation rules, XSLT paths, and schema locations.
- Support hot-reloading of configuration.
- Maintain environment-specific settings.
10. Extensibility Layer
Purpose: Allows the engine to be extended with new features.
Responsibilities:
- Plug-in architecture for new connectors or processors.
- Support for custom transformation modules.
- Enable versioning of transformation logic.
This modular architecture ensures that the transformation engine is scalable, maintainable, and adaptable to evolving enterprise integration needs.
🔌 Input Layer
The input layer is responsible for ingesting data from a variety of external systems. These systems may include:
- Custom Applications – internally developed tools or services.
- Enterprise Applications – such as ERP (e.g., SAP), CRM (e.g., Salesforce), or HRMS.
- Packaged Solutions – off-the-shelf software with export capabilities.
- Third-Party Services – external APIs, SaaS platforms, or data providers.
These systems connect to the pipeline through connectors, which may be:
- File-based (e.g., FTP, SFTP, shared folders)
- API-based (REST, SOAP)
- Messaging systems (e.g., Kafka, RabbitMQ)
- Database connectors (ODBC, JDBC)
Each connector is responsible for fetching or receiving data and converting it into a standard XML format for further processing.
- Data flow: Input XML → Transformation → Output
- Error handling and logging
- Performance considerations
4. Step-by-Step Implementation
a. Preparing the Input XML
- Schema validation (XSD)
- Sample input data
b. Writing the XSLT Stylesheet
- Templates and XPath
- Conditional logic and loops
- Output formatting (HTML, XML, Text)
c. Integrating XSLT in C#
- Loading and applying XSLT using
XslCompiledTransform - Handling parameters and output
- Code snippets and best practices
5. Advanced Topics
- Using multiple XSLT transformations
- Dynamic XSLT loading
- Transforming large XML files (streaming)
- Security considerations (e.g., XXE attacks)
6. Testing and Debugging
- Tools for testing XSLT (e.g., Visual Studio, online editors)
- Unit testing in C#
- Common pitfalls and how to avoid them
7. Deployment and Automation
- Packaging the pipeline as a service or CLI tool
- Scheduling transformations (e.g., with Windows Task Scheduler or Azure Functions)
- Logging and monitoring
8. Real-World Example or Case Study
- End-to-end example with code
- Before and after transformation
- Lessons learned
9. Conclusion
- Recap of key takeaways
- When to use this approach
- Further reading and resources
10. Appendix
- Sample code repository (GitHub link)
- Useful tools and libraries
- References and documentation links