Semantic Kernel Vector Memory using Azure Search
This post highlights the benefits of Semantic Kernel vector memory and its use in developing AI Agents. It also shows how to utilize Azure Search to store and retrieve the vectors and use them in the AI Agents.
What is Semantic Kernel?
Semantic Kernel is an SDK by Microsoft which helps us to write AI Agents. These AI Agents are highly collaborative and can use different LLMs to infer and act like humans. It helps us develop agents that are intelligent, autonomous and adaptable. Semantic Kernel has many features that helps us to do the mundane coding taks systematically and at a good level of abstraction. One such feature is Vector Memory which is main topic of this blog post.
Semantic Kernel Vector Memory
The vector memory feature in Semantic Kernel allows us to store and manage embeddings in a vector store. This store can be either in-memory or backed by an external database, depending on the use case. The vector memory is what gives an agent its power to remember and infer the things to better arrives at a decision. This is used as a basis for RAG based automation. Semantic Kernel supports variety of vector stores that can be found here.
Key Characteristics
- In-Memory Storage: The vector store can operate entirely in memory, which allows for high-speed operations and quick access to data. This is ideal for scenarios where performance is critical, and the data does not need to be persisted long-term.
- Support for Various Data Types: The vector store supports a wide range of data types, including strings, numbers, and custom objects. This allows it to be suitable for variety of use cases.
- Multiple Vectors per Record: The vector store can handle multiple vectors within a single record, allowing for complex data representations and more detailed embeddings.
- Advanced Querying Capabilities: The vector store supports advanced querying capabilities, including filtering and full-text search, which enhances its utility in data retrieval applications.
Benefits of Semantic Kernel Vector Memory Integration
Semantic Kernel is a powerful tool that enables the generation of embeddings for text data. These embeddings are numerical representations of text that capture the semantic meaning of the content. The benefits of using Semantic Kernel include:
- Improved Search Accuracy: By converting text into embeddings, search algorithms can better understand the context and relevance of the data, leading to more accurate search results.
- Enhanced Data Analysis: Embeddings allow for advanced data analysis techniques, such as clustering and classification, which can uncover hidden patterns and insights.
- Scalability : Semantic Kernel can handle large volumes of data, making it suitable for enterprise-level applications.
What is Azure Search?
Azure Search is a cloud-based search service that provides powerful indexing and querying capabilities. It is essential for:
- Efficient Data Retrieval: Azure Search enables fast and efficient retrieval of data from large datasets.
- Advanced Querying: With support for complex queries, Azure Search allows users to perform sophisticated searches and filter results based on various criteria.
- Integration with Other Azure Services: Azure Search seamlessly integrates with other Azure services, such as Azure Cognitive Services and Azure Machine Learning, to provide a comprehensive data processing solution.
- Skill Set: Azure Search is a powerful tool that allows you customized the retrival, extraction, transformation of content by using skill pipelines.
Demo Application
In this blog post, I will demonstrate how to use Semantic Kernel and Azure Search to generate and store embeddings for text data. I will create an EmbeddingEngine class that interacts with the vector store and the text embedding generation service to generate embeddings for text paragraphs and upload them to a specified collection in Azure Search.
Prerequisites
You will a need a few things to get started with this demo:
- Azure Subscription: You will need an Azure subscription to create an Azure Search service. I am assuming you already have created a Azure Search service.
- Azure Search Service: Create an Azure Search service in the Azure portal.
- Azure OpenAI Endpoint: Obtain the deployment name, endpoint, and API key for the Azure OpenAI endpoint. This you need to put in AppSetting.cs file if you are following the sample code.
- Azure Search URL and Key: Obtain the Azure Search URL and key for the Azure Search service.
Understanding the EmbeddingEngine Class
The EmbeddingEngine class holds the code to generate and store the embeddings in a vector store. The class works at an abstraction that does the work using interfaces and methods as defined by Semantic Kernel. This enable the plugin & plug model, in which the core implementation remains the same and actual embedding algorithm or physical vector store can be changed without modifying this class.
The class is declared as follows:
1
2
3
4
internal class EmbeddingEngine(IVectorStore vectorStore, ITextEmbeddingGenerationService textEmbeddingGenerationService)
{
// Methods to generate and upload embeddings
}
As a part of DI, the EmbeddingEngine class is injected with a IVectreStore and ITextEmbeddingGenerationService. These are interfaces that define the methods for interacting with the vector store and generating text embeddings, respectively. The concrete implementation of these interfaces is provided by the Semantic Kernel configured during its creation process. We will see how to configure the kernel in the later part of this blog post.
IVectorStore and ITextEmbeddingGenerationService are interfaces that define the methods for interacting with the vector store and generating text embeddings, respectively.
The GenerateEmbeddingsAndStore method in the EmbeddingEngine class is responsible for generating embeddings for each document record and uploading them to the specified collection. Here is the code snippet for this method:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public async Task GenerateEmbeddingsAndStore(String collectionName, IEnumerable<DocumentRecord> documentRecords)
{
var collection = vectorStore.GetCollection<String, DocumentRecord>(collectionName);
await collection.CreateCollectionIfNotExistsAsync();
foreach (var record in documentRecords)
{
// Generate the text embedding.
Console.WriteLine($"Generating embedding for record: {record.RecordId}");
record.TextEmbedding = await textEmbeddingGenerationService.GenerateEmbeddingAsync(record.Text);
// Upload the text Record.
Console.WriteLine($"Upserting record: {record.RecordId}");
await collection.UpsertAsync(record);
Console.WriteLine();
}
}
NOTE Notice how the method utilizes the
textEmbeddingGenerationServiceto generate embeddings calls and theUpsertAsyncto store the embeddings in the specified vector collection.
Creating Record Definition class
To store the embeddings in the vector store, we need to define a record class that represents the data to be indexed. The Record definitions are used to create structured representations of the data that will be indexed in Azure Search. The DocumentRecord class is an example of a record definition that I created to demonstrate this. The fields in this class are decorated with attributes that specify how the data should be indexed in vector store.
Here is the code snippet for the DocumentRecord class:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
internal class DocumentRecord
{
/// <summary>A unique key for the text Record.</summary>
[VectorStoreRecordKey]
public required String Key { get; init; }
/// <summary>A uri that points at the original location of the document containing the text.</summary>
[VectorStoreRecordData]
public required String DocumentUri { get; init; }
/// <summary>A uri that points at the original location of the document containing the text.</summary>
[VectorStoreRecordData(IsFilterable =true, IsFullTextSearchable =true)]
public required String Title { get; init; }
/// <summary>The id of the Record from the document containing the text.</summary>
[VectorStoreRecordData]
public required String RecordId { get; init; }
/// <summary>The text of the Record.</summary>
[VectorStoreRecordData(IsFilterable = true, IsFullTextSearchable = true)]
public required String Text { get; init; }
/// <summary>The embedding generated from the Text.</summary>
[VectorStoreRecordVector(1536)]
public ReadOnlyMemory<float> TextEmbedding { get; set; }
}
We have define a key, document uri, title, record id, text and text embedding fields in the DocumentRecord class.
- The VectorStoreRecordKey attribute is used to specify the key field, which uniquely identifies each record.
- The VectorStoreRecordData attribute is used to specify the data fields that will be indexed in the vector store.
- The IsFilterable and IsFullTextSearchable properties are used to specify the filtering and full-text search capabilities of the field. Such fields can be used to filter or search the records based on the values of these fields.
- The VectorStoreRecordVector attribute is used to specify the embedding field, which stores the embeddings generated from the text data.
- The length of this vector is specified as 1536, which is the default length for the embeddings generated by the Azure OpenAI text embedding generation service. You can modify this value based on the length of the embeddings generated by the text embedding generation service you are using.
Using Record Definitions to Create an Index
The GetDocumentRecord method in the EmbeddingEngine class creates instances of DocumentRecord based on the input text. These records are then used to create an index in Azure Search. Here is the code snippet for this method:
Feel free to change the deault values.
1
2
3
4
5
6
7
8
9
10
11
12
13
public DocumentRecord GetDocumentRecord(KeyValuePair<String, String> entry)
{
var key = Guid.NewGuid().ToString();
return new DocumentRecord
{
Key = key,
DocumentUri = $"https://www.fsinvest.com/{key}",
RecordId = key,
Text = entry.Value,
Title = entry.Key,
};
}
Once the DocumentRecord instances are created, they are used to create an index in Azure Search. The CreateCollectionIfNotExistsAsync method in the GenerateEmbeddingsAndStore method is responsible for creating the collection in the vector store. You would see something similar to this in your Azure Search Index
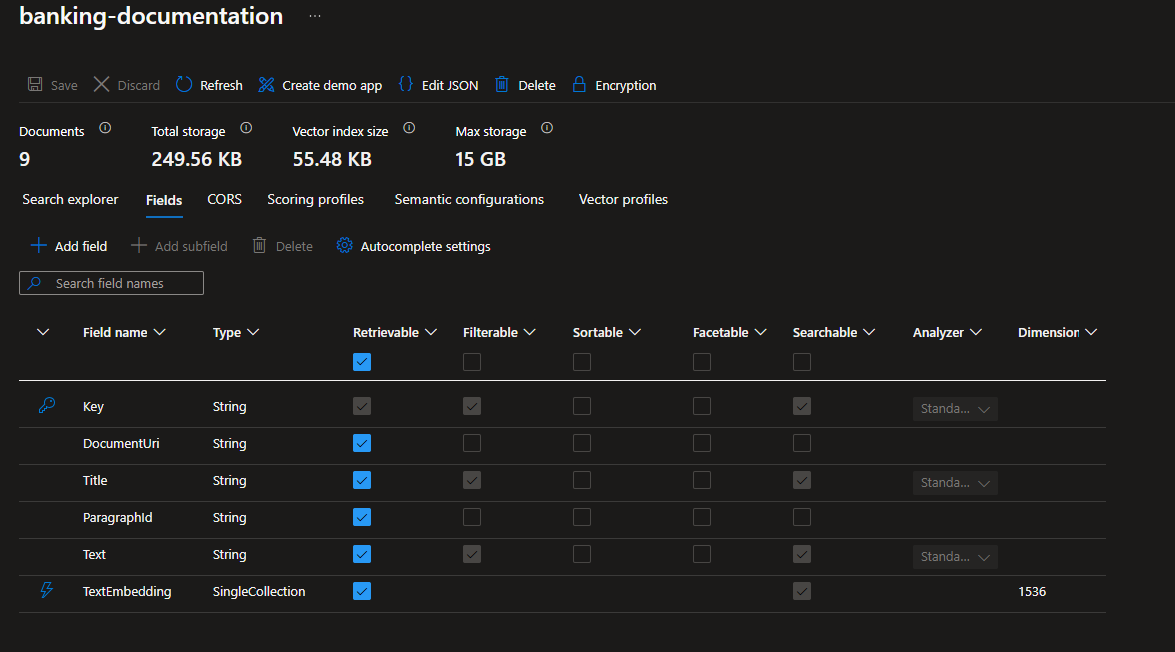
Setting up the Azure OpenAI service
For this demo app, we need a Azure OpenAI service configured in Azure. We also need to deploy the text-embedding model so that the code can use it to generate embeddings.
For step-by-step process on how to create the Azure OpenAI service, refer to my other post here.
NOTE The Azure OpenAI service is a paid service. You will be charged based on the usage of the service. Make sure to check the pricing details before using the service.
Create a AppSetting class
We will use this class to provide the URL and key for the Azure Search service and the Azure OpenAI endpoint. Here is the code snippet for the AppSetting class:
1
2
3
4
5
6
7
8
internal static class AppSetting
{
public static String AzureSearchURL = "https://<your-search-service-name>.search.windows.net";
public static String AzureSearchKey = "<your-search-service-key>";
public static String Endpoint = "<your-endpoint>";
public static String Key = "<your-key>";
public static String EmbeddingModelDeploymentName = "<your-deployment-name>";
}
Create a AzureSearchEmbeddingProcessor class
We will use this class to construct a Semantic Kernel instance and then invoke the embedding for a ficticious banking manual. The banking manual is a JSON file which can be found here.
1
2
3
4
5
6
7
internal class AzureSearchEmbeddingProcessor
{
public async Task GenerateEmbeddings()
{
}
}
Instantiating and Configuring the Kernel
The first step to leverage the capabilities of Semantic Kernel and Azure Search is to create an instantiate and configure the kernel. This involves setting up the Azure OpenAI endpoint and the Azure AI Search-based vector store.
1
var kernelBuilder = Kernel.CreateBuilder();
Configuring Azure OpenAI Endpoint
Once the kernelBuilder instance is created, we need to confgure the Azure OpenAI endpoint using the AddAzureOpenAITextEmbeddingGeneration method. This method requires the deployment name, endpoint, and API key. Here is the code snippet for configuring the Azure OpenAI endpoint:
1
2
3
4
kernelBuilder.AddAzureOpenAITextEmbeddingGeneration(
deploymentName: AppSetting.EmbeddingModelDeploymentName!,
endpoint: AppSetting.Endpoint!,
apiKey: AppSetting.Key!);
Configuring Azure AI Search-based Vector Store
The Azure AI Search-based vector store is configured using the AddAzureAISearchVectorStore method. This method requires the Azure Search URL and the Azure Search key. Here is the code snippet for configuring the Azure AI Search-based vector store:
1
2
3
kernelBuilder.AddAzureAISearchVectorStore(
new Uri(AppSetting.AzureSearchURL),
new AzureKeyCredential(AppSetting.AzureSearchKey));
Integrating the EmbeddingEngine with the Kernel
Once the kernel is configured, we can integrate the EmbeddingEngine with the kernel and use it to generate and upload embeddings.
Adding the EmbeddingEngine as a Plugin
The EmbeddingEngine is registered as a singleton service in the kernel’s service collection. Here is the code snippet for adding the EmbeddingEngine as a plugin:
1
2
kernelBuilder.Services.AddSingleton<EmbeddingEngine>();
Kernel kernel = kernelBuilder.Build();
Generating and Uploading Embeddings
With the EmbeddingEngine integrated into the kernel, we can generate and upload embeddings for the text data. Here is the code snippet for generating and uploading embeddings:
1
2
3
4
5
6
7
8
9
var embeddingEngine = kernel.Services.GetRequiredService<EmbeddingEngine>();
var documentRecords = await GetDocumentRecords("Data\\Banking.json");
foreach (KeyValuePair<String, String> documentRecord in documentRecords)
{
var record = embeddingEngine.GetDocumentRecord(documentRecord);
await embeddingEngine.GenerateEmbeddingsAndStore("banking-documentation", [record]);
}
GetDocumentRecords is a utility method that reads the text data from a JSON file and returns it as a collection of key-value pairs. The GenerateEmbeddingsAndStore method is then called to generate and upload the embeddings for each document record.
Running the application
Now its time to test the application we developed. We need a Main static method to run the application. Here is the code snippet for the Main method:
1
2
3
4
5
public static async Task Main(String[] args)
{
var processor = new AzureSearchEmbeddingProcessor();
await processor.GenerateEmbeddings();
}
Sample Application Code
You can find the complete code for the sample application Semantic Kernel Azure Search Memory. Feel free to fork it and try it out on your own.
I hope you found this post useful, as always the suggestions are welcome. Please feel free to reach out to me or leave a comment below.
Conclusion
In this blog post, we saw we explored the benefits of using Semantic Kernel and the importance of Azure Search in data embedding and retrieval. We have seen how embeddings are generated and stored in vectors. We also covered the creation of record definitions and how they are used to create an index in Azure Search. Finally, we saw how to instantiate and configure the kernel, integrate the EmbeddingEngine as a plugin, and generate and upload embeddings.